Natural Language Processing (NLP) is one of the most dynamic fields in artificial intelligence, driven by breakthroughs in deep learning architectures like transformers. Within the transformer architecture, the TransformerDecoderLayer stands out as a pivotal component that enhances the efficiency and accuracy of NLP models. This article delves into the functionality, benefits, and applications of the TransformerDecoderLayer in building powerful NLP models.
Overview of Transformers in NLP
Transformers gave a paradigm shift to NLP when they were first introduced in the paper titled “Attention is All You Need” by Vaswani et al. Unlike most of the models which used recurrence (like RNNs, LSTMs), transformers make use of attention. This also enables transformers to perform parallel computations to a large extent thereby cutting down the training period while at the same time allowing the model to learn more from huge data sets.


The transformer model follows a transformer architecture which splits the model into an encoder and a decoder. The encoder maps the input sequence into an internal representation and produce, the decoder use the result to produce an output sequence. The TransformerDecoderLayer is responsible for the decoder’s operations; thus, it is a vital part of the majority of recently develope NLP models.
What is a TransformerDecoderLayer?
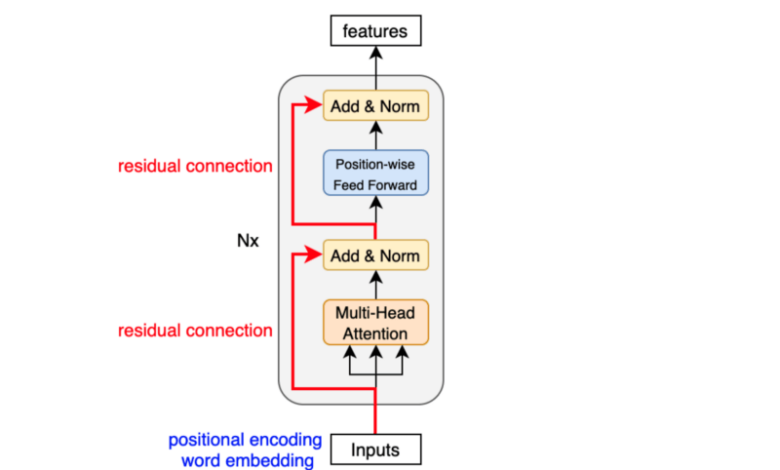
The TransformerDecoderLayer is an integral component of the transformer structure that is use when synthesizing output sequences during decoding. It is intend for the reconstruction of the subsequent word out of the contextual information on the one hand, and the information from the encoder and the words generate earlier on the other hand. As mentioned above, each of the TransformerDecoderLayer involves several components which produce accurate predictions.
Read Also: GroundCloud IO
Key Components of TransformerDecoderLayer
- Self-Attention Mechanism: This mechanism helps the model to give certain importance to different parts of the input sequence and just ignore everything around. Self-attention enables the model to discover the dependencies between the words and long-range dependencies, which is very significant in making the right predictions.
- Encoder-Decoder Attention: Self-attention is mainly used to work with the generate sequence, and the encoder-decoder attention gives the decoder access to the context that is generate by the encoder. This process of bi-directional attention provides a control where the output has a context to the input it has seen.
- Feedforward Neural Networks: From the attention layers, a feedforward neural networks is able to process the output that results from these layers. It is worth noticing that these networks introduce non-linear transformations that enhance the model’s capabilities to grasp intricate structures.
- Layer Normalization and Residual Connections: Residual connections and layer normalization are used after each of the sub-layers; namely self-attention, encoder-decoder attention, and feedforward neural networks. This design aids the process of making training more stable while enabling the use deeper model architectures without compromising the flow of gradients.
How TransformerDecoderLayer Functions
The TransformerDecoderLayer operates by sequentially processing inputs and utilizing attention mechanisms to generate output sequences. Here is a step-by-step breakdown of its function:
- Applying Self-Attention: In this case, the input sequence goes through the self-attention process. This computes attention scores which is deciding how much each word should be attend or focus as compared to the other words in the sequence. The end product generated is a representation of all the words in the input with relation to each other.
- Encoder-Decoder Attention Processing: Subsequently, the layer is encoder-decoder attention that assists in identifying the relevance brought by the encoder’s output. This process helps in making sure that the text which is generated is in harmony with the original text especially in situations where one is translating between a source language and a target language or even summarizing.
- Feedforward Network Transformation: From the above descriptions, it can be seen that the outputs from the attention mechanisms are input to an FNN, as shown in figure.This network applies additional transforms to gain additional relationships.
- Normalization and Residual Connections: Each step passes through layer normalization and residual connections so that the model is stable during training, and the model learns multiple features in the data.
Benefits of TransformerDecoderLayer in NLP Models
The TransformerDecoderLayer offers several advantages that make it a valuable component in modern NLP models:
- Parallel Processing Capability: Unlike traditional sequential models, the TransformerDecoderLayer can process input sequences in parallel. This parallelism significantly speeds up training and enables the handling of larger datasets.
- Better Understanding of Long-Range Dependencies: The self-attention mechanism is particularly adept at capturing dependencies across long sequences. This ability is essential for tasks like translation and text summarization, where context matters greatly.
- Improved Model Flexibility and Customization: By the design of the TransformerDecoderLayer which is highly modular any of the described customizations can be easily done. That allows developers to build more levels to create more powerful models or adjust the architecture of existing ones when necessary.
- Enhanced Performance on Various NLP Tasks: Schuster and Nasakh’s novel approach of integrating self-attention, encoder-decoder attention and feedforward layers results in top of the line NLP performance in tasks comprising text generation, question answering and sentiment analysis.
Applications of TransformerDecoderLayer in NLP
The TransformerDecoderLayer is crucial in many NLP applications, providing advanced capabilities for generating high-quality text and understanding context:
1. Machine Translation
The most common use is called machine translation, and the TransformerDecoderLayer makes it possible to generate correct and semantically appropriate translations of the input text. The encoder-decoder attention mechanism acts as a kind of check to make sure that the output language stays more or less correct with regards to the input language.
2. Text Summarization
In the case of text summarization tasks, there’s the TransformerDecoderLayer which makes it easy to write abbreviated documents or documents that have summaries without missing important aspects. This way it is able to summarize a document and come up with a summary that is reasonable and understandable.
3. Chatbots and Conversational AI
While developing conversational AI, chatbots are trained on models which consists of TransformerDecoderLayers with the aim of being able to produce contextually relevant and human-like responses. Due to the fact that these models can process long range dependencies as well as contextual information these are very useful in real time interaction.
4. Question Answering Systems
Namely, models crafted with the help of TransformerDecoderLayers are perfect when it comes to answering questions based on context. The dual attention mechanisms make sure that the responding answers are correct as well as pertinent to the user’s question.
Challenges and Considerations with TransformerDecoderLayer
Despite its advantages, there are challenges and considerations when using the TransformerDecoderLayer in NLP models:
- High Computational Cost: The self-attention mechanism, especially when processing long sequences, can be computationally expensive. This requires significant memory and processing power, making it challenging to deploy in real-time or resource-constrained environments.
- Large Data Requirements: Effective training of models incorporating TransformerDecoderLayers demands large datasets. This is especially true for high-quality NLP tasks, where data diversity and volume significantly impact model performance.
- Model Interpretability: While transformers provide impressive results, interpreting the decisions made by models using TransformerDecoderLayers can be difficult. This lack of transparency can be a drawback in applications where explainability is crucial.
- Overfitting Risks: Due to their high capacity, models with TransformerDecoderLayers can overfit if not properly regularized, especially when trained on limited or biased datasets.
Future Directions for TransformerDecoderLayer Research
Research is ongoing to address the challenges and further improve the efficiency and capability of the TransformerDecoderLayer:
- Efficient Attention Mechanisms: Researchers are exploring sparse and efficient attention mechanisms to reduce computational costs without compromising performance. This innovation could lead to more scalable and efficient NLP models.
- Knowledge Distillation and Model Compression: Knowledge distillation involves compressing large models into smaller, faster versions without significant loss of performance. This technique could make models with TransformerDecoderLayers more accessible for real-world applications.
- Hybrid Architectures: Combining the strengths of transformers with other architectures like CNNs and RNNs could lead to hybrid models that balance computational efficiency with high performance.
- Improved Interpretability Methods: Enhancing the interpretability of models using DecoderLayer is an active area of research. Better visualization tools and explanation methods can help users understand model decisions, increasing trust and reliability.
Conclusion
With these orientations, the TransformerDecoderLayer or transformer model has become an essential component taking part in state-of-the-art innovations in the field. Its capability to cope well with interdependencies, serial or parallel computations, and program in various applications that are essential in NLP makes it unique. But yet, there are limitations like computational complexity and data demands which has to be overcome in order to get the best out of it. As the research goes on, the TransformerDecoderLayer will remain an important part in boosting of NLP technologies by providing the better, stronger, and more flexible models for the future.



